
PubChem is a database of chemical compounds and their biological activities, published by the National Center for Biotechnology Information (NCBI), it is freely accessible and contains over 100 million compounds. Its databases are provided by the United States National Library of Medicine (NLM), which is the world’s largest biomedical library and the developer of electronic information services that delivers data to millions of scientists, health professionals and members of the public around the globe and is a component of the National Institutes of Health (NIH).
It was launched in 2004 by the National Center for Biotechnology Information (NCBI) as a free, online database of chemical structures and their associated biological activities. The database was designed to support the needs of the scientific community, including researchers, students, and clinicians. The database contains over 100 million chemical structures and associated information on their biological activities. The database is updated daily with new data from a variety of sources, including scientific journals, patents, and government databases.[1]
PubChem contains information about chemical substances and their biological activities. It also contains information on the structure and properties of these substances. Furthermore, it contains information on the synthesis, production, and use of these substances and is divided into three main sections: The first section, called the „Compound“ section, contains information on the chemical structure of a substance, as well as its physical and chemical properties. The second section, called the „BioAssay“ section, contains information on the biological activity of a substance. The third section, called the „Substance“ section, contains information on the synthesis, production, and use of a substance. Accordingly to the sections, it has three main databases: the Substance database, the Compound database, and the BioAssay databse.
Data Sources
The data comes from a variety of sources, including the US National Library of Medicine, the European Bioinformatics Institute, and the Chinese National Chemical Library. The data sources include the NIH/NCBI, EPA, FDA, and other government agencies. Besides government agencies, data is accepted from academic institutions and private companies. Contributors submit data to the database, which is then made available to the public, however contributors must first register with the site. “PubChem accepts chemical structures, names, links, spectra and associated bioassay test results.”[2] Submissions are approved by a moderator before being made public.
Data Counts
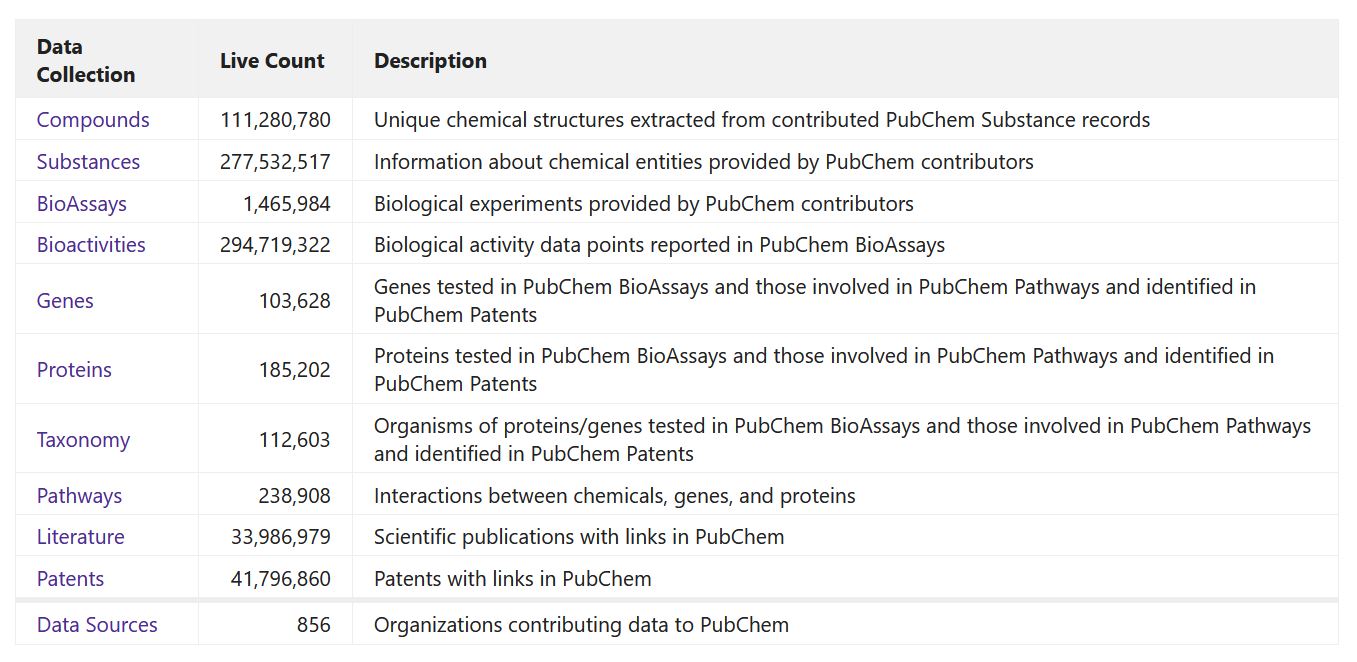
The above image, showing the current data count (screenshot taken on the 6th of May 2022), proves that the database contains over 100 million compounds and over 250 million substances. Having all this information in one place is a great resource for researchers.
Website Redesign
The website itself went through a complete redesign several years ago, with added new features and enhancements, and improved search functionality. According to their own blog, these were the key changes that had taken place: “The categorization describing the organization types providing content was simplified. Sources of hierarchical classifications and textual annotations are now included. There is now a unified data source table containing all primary information. The updated interface provides new and improved capabilities to navigate as a function of data type, category, and country, while also including keyword searching, counts, and geographic visualization.”[3]
Changes also applied to the filtering capability of the website, that now include a panel summarizing by count the key aspects of the sources and offering to filter the data sources listed by type, by category, by status, and by geographic region. Sorting has also been improved allowing users to sort by record counts and by modification date.[4] These changes lead to a more user-friendly experience when using the website.
Historically, PubChem was integrated with Entrez, which was NCBI’s primary text search and retrieval system. Entrez is a search engine that allows users to search for biomedical data in the database. Entrez search results can be filtered by data type, source, or organism. Entrez search is different from regular search by allowing users to specify the database in which to search. However, users found it difficult to navigate multiple Entrez search interfaces, having to use separate interfaces for compound, substance and bioassay searches. Entrez also did not support newer content, such as patents.[5] The redesign incorporated a unified chemical search interface that supports text search across all of PubChem.
The Current search options
The current search offers looking up compounds, substances and bioassays. (There is chemical information available from hundreds of data sources and PubChem organizes them into multiple data collections, including Substance, Compound, BioAssay, Protein, Gene, Pathway, and Patent.[6]) The homepage also offers suggestions of what to try to use as searched terms (covid-19, aspirin, EGFR, C9H8O4, 57-27-2, C1=CC=C(C=C1)C=O, InChI=1S/C3H6O/c1-3(2)4/h1-2H3).
The syntax of PubChem searches has the following rules:
- A search term can be a compound name, a compound identifier, or a chemical structure.
- A search term can be a single word or multiple words.
- A search term can be a phrase enclosed in double quotation marks.
- A search term can be a regular expression.
- A search term can be a wildcard.
- Multiple search terms can be combined using Boolean operators.
Boolean operators
There are three Boolean operators that can be used in searches: AND, OR, and NOT. AND: The AND operator is used to combine two or more search terms so that all of the terms must be present in the results. OR: The OR operator is used to combine two or more search terms so that any of the terms can be present in the results. NOT: The NOT operator is used to exclude a term from the results.
Draw search
You can draw the structure, upload ID list, browse data or use the periodic table. Draw search provides a way to search for chemical structures. It differs from regular search by allowing users to search for structures by drawing them instead of using keywords. Draw structure uses a SMILES identifier, meaning that the user can input a SMILES string to search for a specific structure, or they can draw a structure and PubChem will attempt to generate a SMILES string that represents that structure. This can be manually change to a SMARTS query, which is a query that uses the SMARTS search algorithm.[8]
The input structure can be provided using popular line notations or drawn with the PubChem Sketcher. IT supports various types of structure searches, including identity search, 2-D and 3-D similarity searches, and substructure and superstructure searches.
Kim S, Exploring Chemical Information in PubChem, Curr Protoc. 2021., 3.5.2022, online: https://pubmed.ncbi.nlm.nih.gov/34370395/
Data Organization
Data Organization on PubChem is not consistent. There is no one answer to this question as the organization of data varies depending on the specific data set. However, in general, data here is organized into databases, which are then further divided into smaller data sets. (“Data sources submit Substance and/or BioAssay records. PubChem derives Compound records from unique structures.”[9])
Data is organized into:
- Substances (assigned a unique Substance Identifier – SID and archived allowing the investigation of previously submitted versions),
- Compounds (when one or more Substance records contains structures that can be standardized into same chemical structures, a single Compound record is generated with its identifier – CID, forming useful summaries of all the information available),
- BioAssays (data describing biological assay experiments on substances, with each experiment from each data source being assigned a unique identifier – AID, these record contain active/inactive determinations of bioactivity),
- Targets (summarizing data applicable to a given gene or protein target),
- Pathways (information about the biological pathway, important for providing a context for biological activity),
- Taxonomy (a curated classification and nomenclature for all of the organisms in the public sequence databases[10]),
- Patents (information including patent title, abstracts, application and publication dates, applicant, inventor, and classification for the given substance or compound[11]).
Index
Compounds are indexed by their CAS Registry Numbers. PubChem indexes substances using a variety of identifiers, including CAS Registry Numbers, IUPAC International Chemical Identifiers, and Substance and Compound IDs. Bioassays are indexed by the target molecule, the type of assay, and the type of activity.
License
This is a free, open database that is available to the public under the terms of the Creative Commons Zero (CC0) license.[12] This license allows anyone to copy, modify, distribute, and use the data in the database without restriction. PubChem does not currently use different licenses for different parts of the database. All of the data is free to use, distribute, and modify. There are no licensing restrictions on the use of the data.
Examples of usage
Examples of PubChem usage are:
- To find the structure of a compound (it can be used to find the structure of a compound by searching for its name or CAS number),
- To find the properties of a compound( it can be used to find the properties of a compound, such as its melting point, boiling point, and solubility),
- To find the toxicity of a compound (it can be used to find the toxicity of a compound by searching for its name or CAS number).
In summary, what are 5 key points one should know about PubChem? 1. It is a database of chemical information. 2. It is operated by the U.S. National Institutes of Health (NIH). 3. It contains data on over 100 million chemical compounds. 4. It is free to use. 5. PubChem is a valuable resource for scientists and researchers.
This work has used the Hardvard citation style.
[1] PubChemDocs. 2022. About. [online] Available at: <https://pubchemdocs.ncbi.nlm.nih.gov/about> [Accessed 1 May 2022].
[2] PubChemDocs. 2022. Submissions. [online]. <https://pubchemdocs.ncbi.nlm.nih.gov/submissions> [Accessed 1 May 2022].
[3] PubChemDocs. 2022. New PubChem [online]. <https://pubchemdocs.ncbi.nlm.nih.gov/2016/10/25/new-pubchem-data-sources-page/> [Accessed 1 May 2022].
[4] PubChemDocs. 2022. New PubChem [online]. <https://pubchemdocs.ncbi.nlm.nih.gov/2016/10/25/new-pubchem-data-sources-page/> [Accessed 1 May 2022].
[5] PubChemDocs. 2022. Entrez [online]. <https://pubchemdocs.ncbi.nlm.nih.gov/advanced-search-entrez> [Accessed 6 May 2022].
[6] Kim S, „Exploring Chemical Information in PubChem“, Curr Protoc. 2021. [online]. <https://pubmed.ncbi.nlm.nih.gov/34370395/> [Accessed 3 May 2022].
[7] Kim S, „Exploring Chemical Information in PubChem“, Curr Protoc. 2021. [online]. <https://pubmed.ncbi.nlm.nih.gov/34370395/> [Accessed 3 May 2022].
[8] The SMARTS search algorithm is a heuristic search algorithm that is used to find solutions to problems with large search spaces. The algorithm is based on the idea of using a heuristic function to guide the search through the search space. The heuristic function is used to estimate the cost of reaching the goal state from the current state. The algorithm then uses this information to guide the search towards the goal state.
[9] PubChemDocs. 2022. Data organization [online]. <https://pubchemdocs.ncbi.nlm.nih.gov/data-organization> [Accessed 3 May 2022].
[10] PubChem. NCBI Taxonomy. <https://pubchem.ncbi.nlm.nih.gov/source/22056> [Accessed 3 May 2022].
[11] PubChemDocs. Patents [online]. <https://pubchemdocs.ncbi.nlm.nih.gov/patents> [Accessed 3 May 2022].
[12] PubChem, Healthdata, <https://healthdata.gov/dataset/PubChem/dave-j5bi/data> [Accessed 6 May 2022].






{kind=link}