
Úvod
Data jsou v dnešní době jedním z nejdůležitějších aspektů jakéhokoliv výzkumu, avšak je velice obtížné se orientovat v obrovském množství dostupných a stále přibývajících dat na internetu. Povaha a typ dat se liší od disciplíny k disciplíně a každý druh dat má většinou svou doménově specifickou hodnotu. Základní potřebou při provádění výzkumu je pak nalézt odpověď na otázky jako jsou na co, kde a jak spravovat data pro konkrétní výzkum.
A právě informační zdroje a datové repozitáře, jako je Mendeley Data, umožňují lidem objevovat, shromažďovat a sdílet výzkumná data. Usnadňují tedy mj. práci s vyhledáváním, správou, uložením a citací relevantních dat.
Platforma Mendeley Data
Mendeley Data, jakožto součást nizozemského vydavatelství Elsevier, je otevřená cloudová platforma pro správu, ukládání a vyhledávání výzkumných dat v celém jejich životním cyklu. Mendeley Data indexuje tisíce datových repozitářů buď přímo, nebo prostřednictvím DataCite [1] (globální poskytovatel DOI – z anglického Digital Object Identifier, česky „digitální identifikátor objektu“ – pro výzkumná data). To znamená desítky milionů indexovaných datasetů.
Tato online platforma dále umožňuje sdílení citovatelných výzkumných dat, čímž pomáhá ve spolupráci s různými výzkumnými komunitami. Mendeley Data rovněž umožňuje uživatelům vytvořit skupinu pro svůj konkrétní výzkumný projekt, kde spolupracující uživatelé mohou shromažďovat, organizovat, anotovat a sdílet data na jednom místě.
Správa a sdílení dat prostřednictvím datového repozitáře jako je Mendeley Data, tak poskytuje větší publicitu datům, která mají být znovu použita legálním a vědeckým způsobem, připsáním citace. Opakovaná použitelnost dat také dává hodnotu agenturám pro financování za jejich investice do konkrétního výzkumu. [2]
Práce s Mendeley Data
Informační zdroj Mendeley Data nabízí kromě jednoduchého (volného) a pokročilého vyhledávání i tvorbu a následnou správu a archivaci vlastních datasetů.
Tvorba nových datasetů
Vytváření datasetů v Mendeley Data je jednoduchý a uživatelsky přívětivý proces. Po registraci k účtu Mendeley mohou uživatelé vytvářet nové datasety. Jednotlivé soubory lze do datasetu přidávat způsobem „drag and drop“ (přetažením souboru z jednoho místa do druhého) nebo klasickým výběrem souborů z počítače uživatele. Nahrané soubory je pak možné organizovat do složek a podsložek. Lze nahrát jakýkoliv formát souboru. Dostupné úložiště je omezeno na 10 GB na jeden dataset (viz obrázek 1).
Uživatelé jsou dále vyzváni k zadání názvu, přidání přispěvatelů a popisu a přiřazení předmětové kategorie pro dataset. Uživatelé mohou také zahrnout kroky pro reprodukci výzkumných dat zahrnutím, jak byla tato data získána (protokoly/metody). K vytvářenému datasetu je automaticky přidána citace rezervováním DOI. DOI je aktivní po zveřejnění.
Kromě toho jsou uživatelé požádáni, aby si vybrali licenci pro opětovné použití dat. Lze také přidat odkazy na související článek, dataset či software. Publikované datasety lze pak upravovat. Upravené datasety obdrží nové číslo verze. [2]
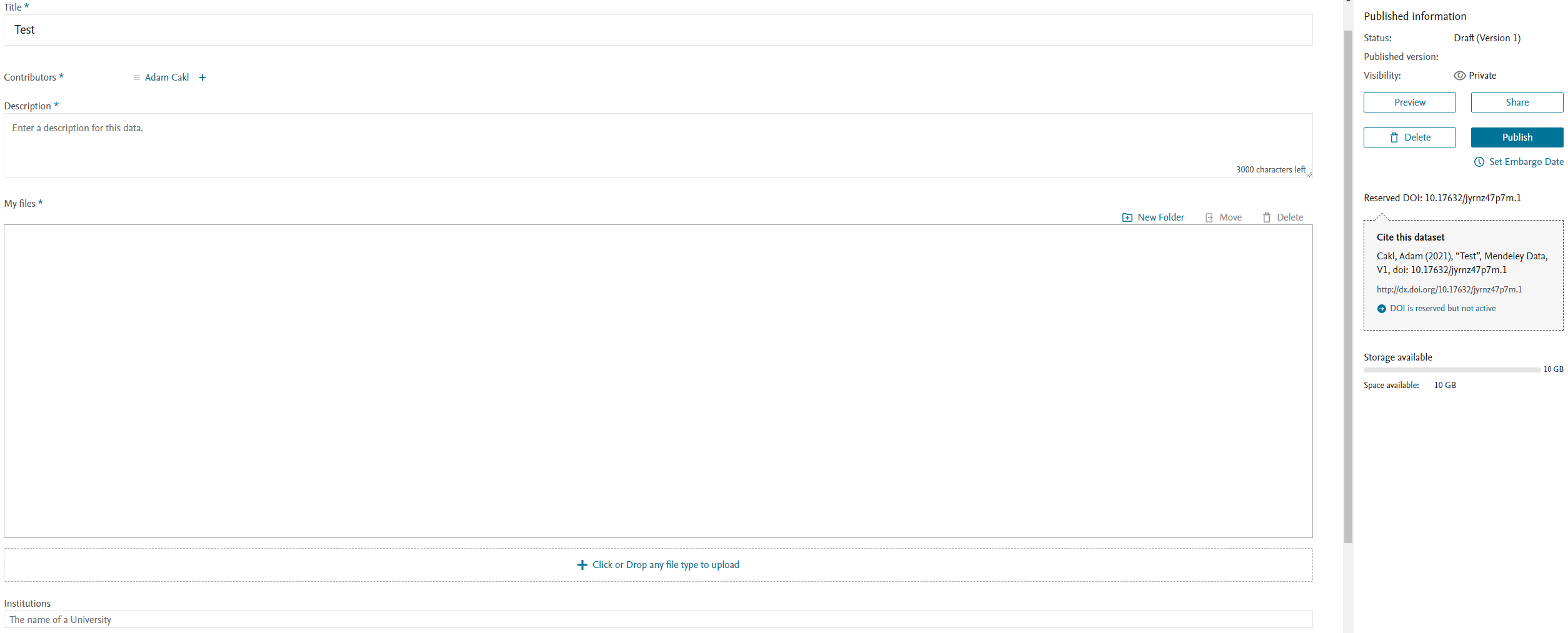
Při vytváření nového datasetu však existují i určitá omezení: [2]
- nelze nahrát již publikované datasety (neboli datasety s již přiděleným DOI)
- datasety musí mít vědeckou povahu a musí sestávat z vědeckých dat
- datasety nesmí obsahovat spustitelné soubory nebo archivy, které nejsou doprovázeny jednotlivými podrobnými popisy souborů
- datasety nesmí zahrnovat obsah chráněný autorskými právy (audio, video, obrázky atd.), ke kterému nevlastníte autorská práva
- datasety nesmí obsahovat citlivé informace (např. podrobnosti o pacientovi, data narození atd.)
Vyhledávání vědeckých dat
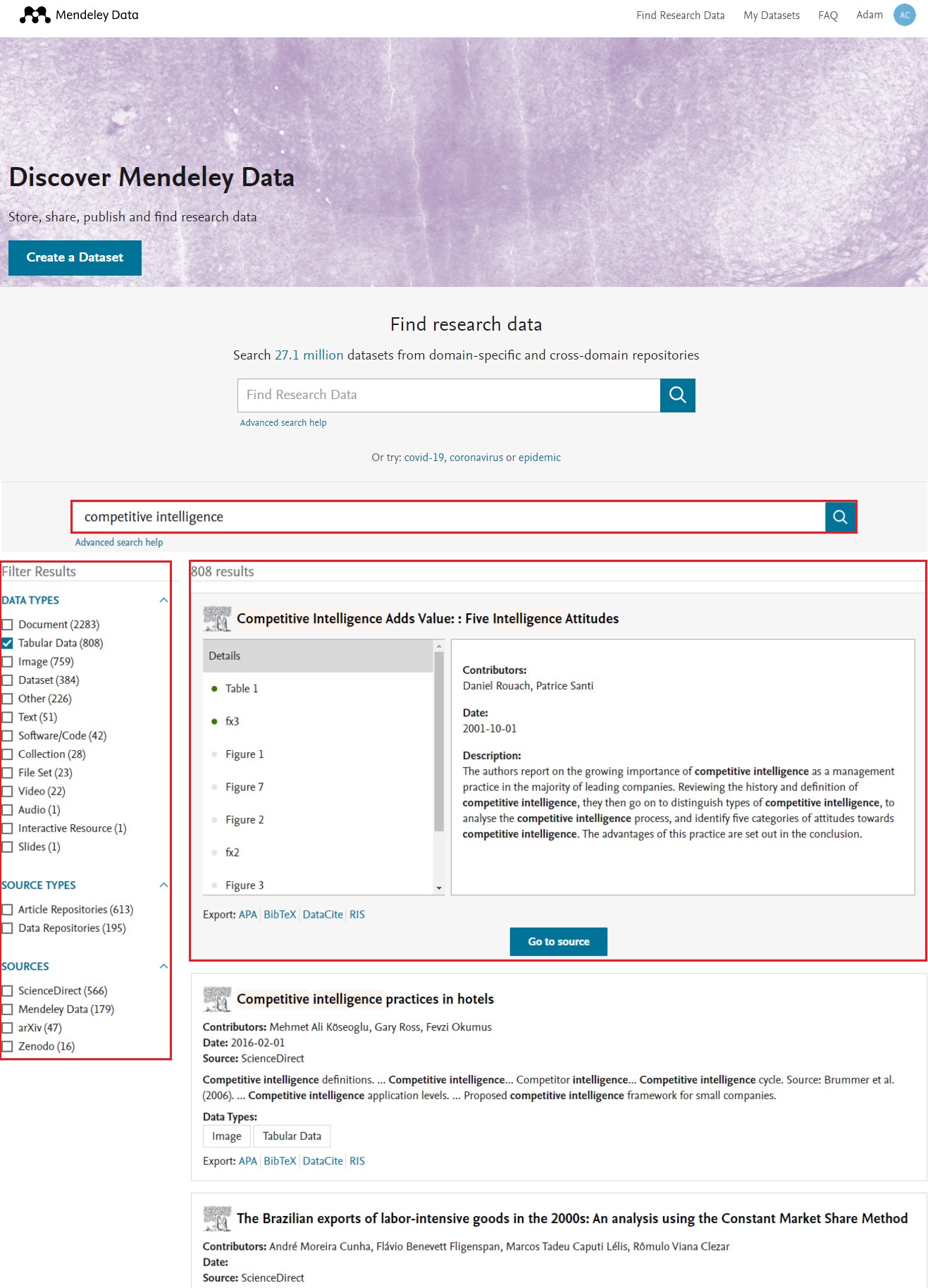
K vyhledávání datasetů a repozitářů lze využít jednoduché vyhledávání, kde na domovské stránce Mendeley Data stačí kliknout na Find Reserach Data, zadat klíčová slova do vyhledávacího pole a spustit vyhledávání.
Výsledky hledání (viz obrázek 2) se zobrazí v pravém panelu stránky a každý jednotlivý výsledek zobrazuje základní informace, jako jsou přispěvatelé, datum, zdroj ad. Podrobnější informace se zobrazí rozbalením výsledku po kliknutí na nadpis, kde se v části podrobnosti (Details) zobrazí další související soubory, pokud některé existují. Po zvolení vhodného výsledku hledání z jednotlivých náhledů lze získat přístup k úplným informacím kliknutím na More Details nebo Go to Source v závislosti na tom, co je právě prohlíženo (např. v závislosti na zdroji dat, kliknutím na Go to Source je umožněno stáhnout, citovat, sdílet nebo exportovat obsah a kliknutím na More information se otevře domovská stránka datasetu, kde je možné stáhnout soubory a mít plný přístup k metadatům).
Výsledky je také možné dále filtrovat zaškrtnutím požadovaného políčka v levém panelu stránky. Lze filtrovat podle datového typu (tabulka, dataset, obrázek, dokument, text, video audio ad.), typu repozitáře (datový nebo repozitář článků) a zdroje (na výběr je mnoho různých informačních zdrojů, např. ScienceDirect, arXiv, IEEE DataPort nebo samotné Mendeley Data). Zatímco je možné provést výběr z více možností při filtrování dle datového typu, při filtrování dle typu repozitáře a zdroje lze zvolit pouze jednu možnost. [2]
Vše je znázorněno a shrnuto na obrázku 2 – vyhledávání na horní straně a výsledky hledání na spodní straně.
Platforma Mendeley Data také umožňuje pokročilé vyhledávání (Advanced search) pomocí syntaxe určené pro různé pokročilé vyhledávání dat, jako je vyhledávání v definovaných polích a použití booleovských operátorů.
K zacílení na jedno nebo více konkrétních polí v datasetu lze využít následující syntax zadáním tzv. kódu pole (z anglického field code, který musí být psán velkými písmeny) a následným zapsáním požadovaného výrazu do závorky. Přehled jednotlivých kódů polí s jejich popisem je následující: [2]
- AUTHOR() – vyhledá autory, jejichž jména obsahují výraz zadaný v závorce v jakékoli části jejich jména
- AUTHOR_ID – podporuje následující ID: Mendeley User ID, Scopus User ID, ORCID a všechna ID uživatelů podporovaná DataCite
- TITLE() – vyhledá nadpisy, které obsahují výraz zadaný v závorce v jakékoli části textu nadpisu
- INSTITUTION() – vyhledá instituce, které obsahují výraz zadaný v závorce v jakékoli části textu nadpisu
- INSTITUTION_ID() – podporuje následující ID: Scopus Institution ID, Scival Institution ID, Mendeley Institution ID
- ID() – vyhledá dokument, který má externí identifikátor obsahující textový řetězec zadaný v závorce
- DOI() – vyhledá dokument, který má DOI identifikátor obsahující textový řetězec zadaný v závorce
- KEYWORDS – filtrování výsledku hledání podle klíčových slov
- SUBJECT_AREA – filtrování výsledku hledání podle kategorií oblasti předmětu
- IS_SUPPLEMENT_TO – vyhledá dokument, který je doplňkem k datové sadě se souvisejícím identifikátorem obsahující textový řetězec zadaný v závorce
Pokročilé vyhledávání navíc podporuje booleovské operátory. Data lze vyhledávat pomocí operátorů AND, OR nebo NOT. Kódy polí lze také použít v jakémkoliv booleovském dotazu, který zahrnuje OR mezi kódy polí a normálními dotazy. Příkladem takového dotazu je např.:
- (competitive intelligence AND AUTHOR(Smith)) OR AUTHOR(Smith AND Johnson) AND INSTITUTION(University of Manchester)
K určení přesné shody textu ve vyhledávání lze použít dvojité uvozovky, a to uvnitř kódu pole i mimo něj. Všechna slova uvnitř uvozovek jsou pak vyhledávána tak, jak jsou zapsána. Alternativně lze použít složené závorky k určení přesné shody textu, ale jsou přijaty pouze jako modifikátor kódu pole a nejsou přijaty ve volném textovém vyhledávání, protože složené závorky nejsou přijímány jako znak ve volném vyhledávání. Příkladem jsou např. tyto dotazy: [2]
- AUTHOR(„John Smith“) OR AUTHOR({Mary Williams})
- „competitive intelligence“
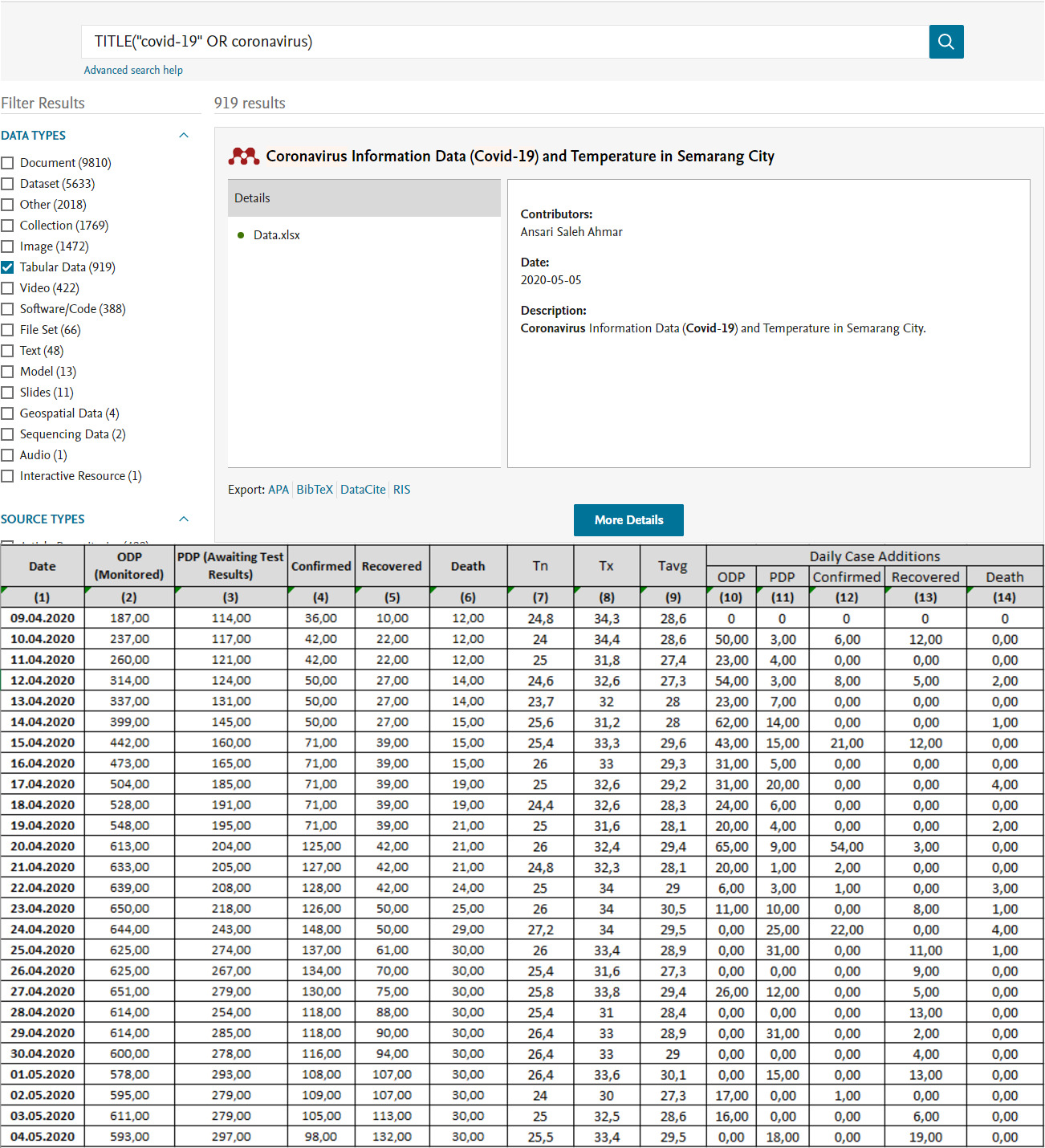
Ukázka výsledku pokročilého hledání vypadá následovně (viz obrázek 3) s využitím tohoto dotazu filtrovaného dle typu zdroje na tabulární data:
- TITLE(„covid-19“ OR coronavirus)
Závěr
Obrovské množství času a finančních prostředků je investováno do sběru nebo generování dat pro konkrétní výzkumnou práci. Ve světě založeném na datech je pak důležitost náležité péče, zpracování a správy výzkumných dat považována za etickou povinnost institucí i vědeckých pracovníků, protože data jsou zásadním přínosem výzkumu.
Mendely Data je otevřený informační zdroj nabízející desítky miliónů vyhledatelných datasetů, které mohou vědečtí pracovníci či akademické instituce volně použít ke generování nových zjištění. Zároveň díky pokročilému vyhledávání a využití vhodné syntaxe je možné zacílit a omezit výsledek vyhledávání na menší množinu relevantních datasetů a ušetřit tak velké množství času. Mendeley Data navíc poskytuje prostor pro správu a uchování výzkumných dat, které po nahrání obdrží DOI, takže na ně lze odkazovat a citovat.
Mendeley Data má však jednu nevýhodu po stránce filtrování výsledků hledání. Filtrování umožňuje vybírat pouze ze tří hlavních skupin, a to dle datového typu, typu repozitáře a zdroje. Není zde však možnost filtrovat dle kalendářních dat. Tuto možnost nenabízí ani pokročilé vyhledávání.
Použité zdroje
[1] Welcome to DataCite [online]. [vid. 2021-01-31]. Dostupné z: https://datacite.org/
[2] Frequently Asked Questions – Mendeley Data [online]. [vid. 2021-02-01]. Dostupné z: https://data.mendeley.com/faq
[3] Mendeley Data [online]. [vid. 2021-02-10]. Dostupné z: https://data.mendeley.com/






{kind=link}