Úvod
Asi každý narazil poslední dobou minimálně na jeden z následujících výrazů: data science, machine learning, quantitative finance… a mnoho dalších příbuzných tzv. „buzzwordů.“ Pojďme se na chvíli vžít do role takového „datového vědce,“ jenž se snaží vyřešit problém, se kterým se dříve nesetkal a neví, odkud začít. Google vyhledávač po zadání příslušných výrazů vrací zpět nejen jejich definice, ale i všemožné instruktáže, amatérské lekce, jejichž kvalita je přinejmenším diskutabilní. Internetový vyhledávač nenabízí odpověď, jelikož se už jedná o poměrně specifické téma a nikdo není schopen pomoci. I v takovém případě se vyplatí sáhnout po nástroji jménem ArXiv.
O ArXiv.org
ArXiv je veřejné uložiště akademických článků a prací v oborech fyziky, matematiky, informatiky (computer science), kvantitativní biologie, pokročilých kvantitativních metod ve finančnictví, elektroinženýrství, ekonomie a dalších příbuzných odvětví. Toto uložiště je ve vlastnictví Cornell University a je financováno komunitně – spoléhá na paušální příspěvky přidružených organizací, jež se k podpoře upisují na pět let.
Důležité je zmínit, že články na ArXivu nepodléhají peer reviews, při nahrávání procházejí pouze kontrolou administrátorského týmu ArXivu složeného z dobrovolníků z řad expertů v příslušných odvětvích. Obsah článků je při schválení nahráván tak, jak je. Proto je třeba se mít na pozoru, neboť se může stát, že publikace nebyla hodnocena jinými vědci či profesionály, kterými by mohla být z nějakého důvodu odmítnuta – například kvůli nedostatkům či nesprávnostem. Ve většině případů se totiž jedná o tzv. preprints, které tyto hodnocení teprve čekají. Pro zveřejnění práce na ArXivu je nutná registrace, pro jejich čtení nikoliv.
ArXiv je populární zejména v oboru statistiky a strojového učení, které patří k nejdynamičtěji se rozvíjejícím mezi výše zmíněnými obory. Pojďme zjistit, jaké jsou tedy jeho největší přednosti, a jaké má naopak nedostatky.
Možnosti vyhledávání
Vraťme se zpět k příkladu s datovým vědcem. Ten řeší specifický problém týkající se klasifikace textových dat – jeho data jsou popsána jen z části, ale on potřebuje mít tyto popisky kompletní. Při vyhledávání na Google se dočetl, že by mu mohla pomoci jedna konkrétní metoda, k níž ale nemůže dohledat žádný postup. Zkusí tedy vyhledat řešení na ArXiv.org.
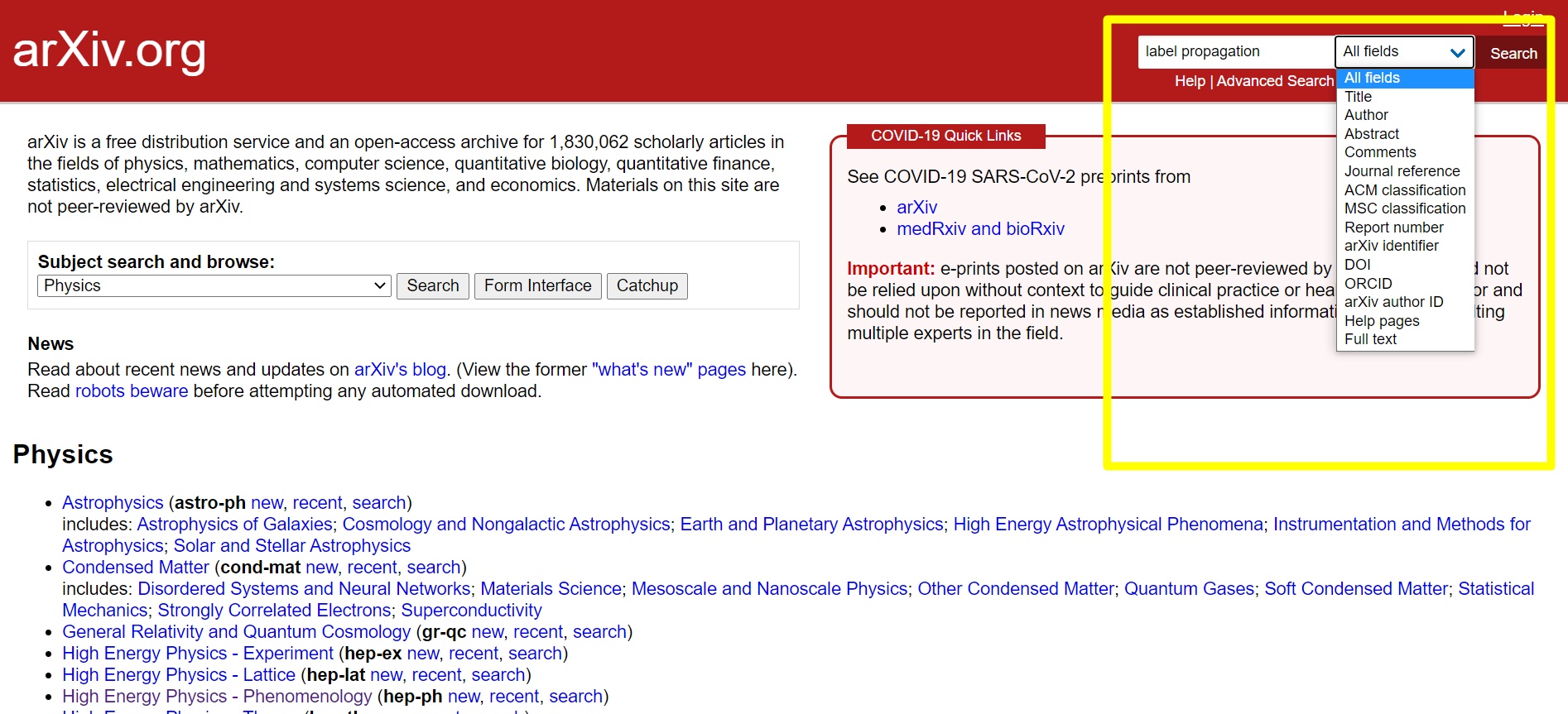 Obrázek 1: Základní vyhledávání na ArXiv.org. [zdroj obrázku: autor]
Obrázek 1: Základní vyhledávání na ArXiv.org. [zdroj obrázku: autor]
Základní vyhledávání na ArXivu nám umožňuje hledat klíčová slova ve všech polích, jež záznamy obsahují, nebo v jednotlivých polích jako například titul, autor či abstrakt. Dostupné je pochopitelně mimo jiné i vyhledávání pomocí DOI, pokud už na začátku víme konkrétně, jaký článek hledáme. Pokud nás ovšem ani jedna možnost neuspokojuje, můžeme zvolit funkci pokročilého vyhledávání.
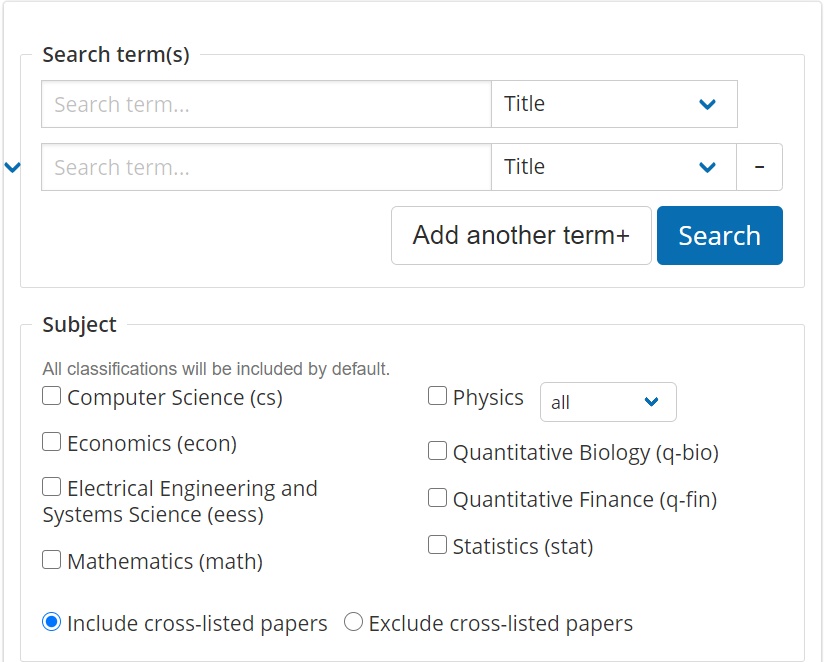 Obrázek 2: Možnosti pokročilého vyhledávání. [zdroj obrázku: autor]
Obrázek 2: Možnosti pokročilého vyhledávání. [zdroj obrázku: autor]
V rámci pokročilého vyhledávání už můžeme volit konkrétní vědecké obory, pomocí kterých chceme výsledky filtrovat. Pokud tedy vezmeme v úvahu případ našeho vědce, upřesníme vyhledávání na obory Computer Science a Statistics. Těchto možností můžeme zvolit více, neboť u většiny článků se obory prolínají a v rámci indexace jsou u článku zmíněny všechny „dotčené“ obory. Další možností pokročilého vyhledávání je upřesnění data, kdy měl hledaný článek vyjít. Uvést můžeme konkrétní datum, měsíc, celý rok, nebo i časové rozpětí definované dvěma daty.
Pokud nehledáme nic konkrétního a na ArXiv jsme zabloudili v rámci studia a objevování nových postupů, čemuž se v některých moderních technologických společnostech věnují celé dny, můžeme si na úvodní stránce jednoduše zvolit požadovaný obor a zobrazí se nám články z posledních pěti dní, kdy došlo alespoň k jednomu nahrání článku. Zatímco u strojového učení se tak počet výsledků k 30. lednu 2021 rovná číslu 92, heslo „Computational finance“ nabízí pouhých 7 článků:
 Obrázek 3: Výsledky hledání pomocí oborů. [zdroj obrázku: autor]
Obrázek 3: Výsledky hledání pomocí oborů. [zdroj obrázku: autor]
Vyhledáváme-li pomocí textového vyhledávání, ať už základního či pokročilého, výsledky našeho dotazu pro každý odpovídající článek zobrazují číslo článku v databázi ArXivu, jeho název, autora či autory, abstrakt (tuto možnost lze vypnout), informaci o datu nahrání a případně doplňující informace – zpravidla zmínky o schválení článku pro účely prezentací na konferencích apod.
Nalezené výsledky můžeme vyfiltrovat podle data oznámení článku, data schválení a nahrání na ArXiv či relevance s ohledem na námi zadaná klíčová slova. Bohužel nelze vyhledávat dle popularity či jiného měřítka oblíbenosti mezi experty v odvětví, což vylučuje možnost hledat řešení mezi těmi nejpopulárnějšími, a tedy dost možná nejpoužívanějšími. To je jeden z nedostatků vyhledávání na ArXivu, ačkoliv se může stát, že na ArXiv už přijdeme z jiné komunitní webové stránky, jež konkrétní hledanou práci zmiňuje.
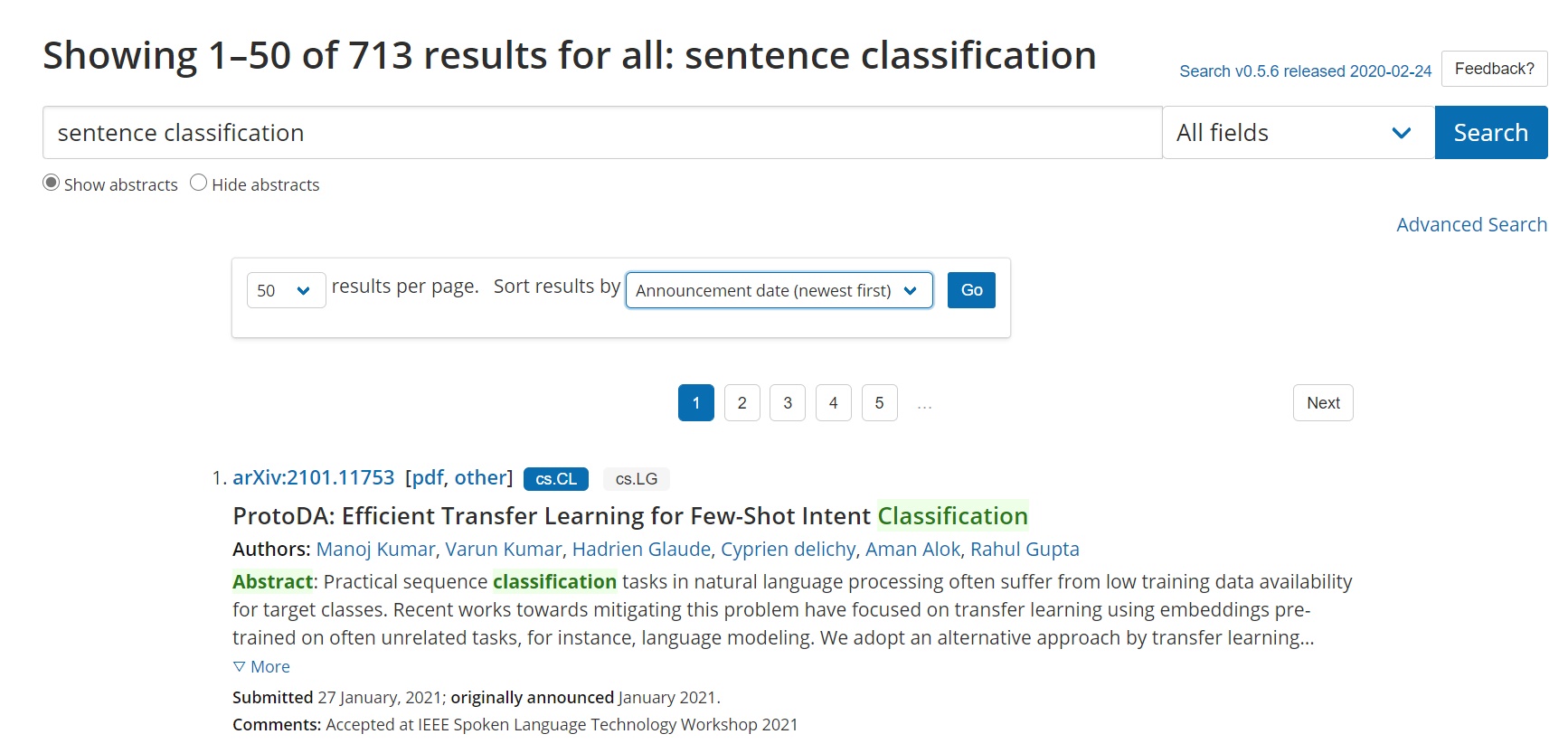 Obrázek 4: Výsledek vyhledávání. [zdroj obrázku: autor]
Obrázek 4: Výsledek vyhledávání. [zdroj obrázku: autor]
Každý záznam má také uveden zkratku kategorie či oboru, ke kterému patří. Na obrázku je to cs.CL, což je zkratka pro „Computation and Language,“ následovaný zkratkou cs.LG, jež odpovídá oboru „Machine Learning.“ Filtrování je, jak bylo zmíněno dříve, poměrně omezené, a proto je dobré již v samém počátku dobře definovat dotaz, pokud možno, v rámci pokročilého vyhledávání. V opačném případě nezbývá než se probrat stovkami a stovkami článků odpovídajícím našim kritériím. V ilustračním případě je to 713 výsledků, jelikož dotaz nebyl zformulován dostatečně konkrétně a nebyly využity pokročilé možnosti vyhledávání.
Pokud tedy nalezneme článek a dle abstraktu se nám jeví jako potenciální pomoc pro náš problém, přejdeme na jeho stránku, jejíž podoba je následující:
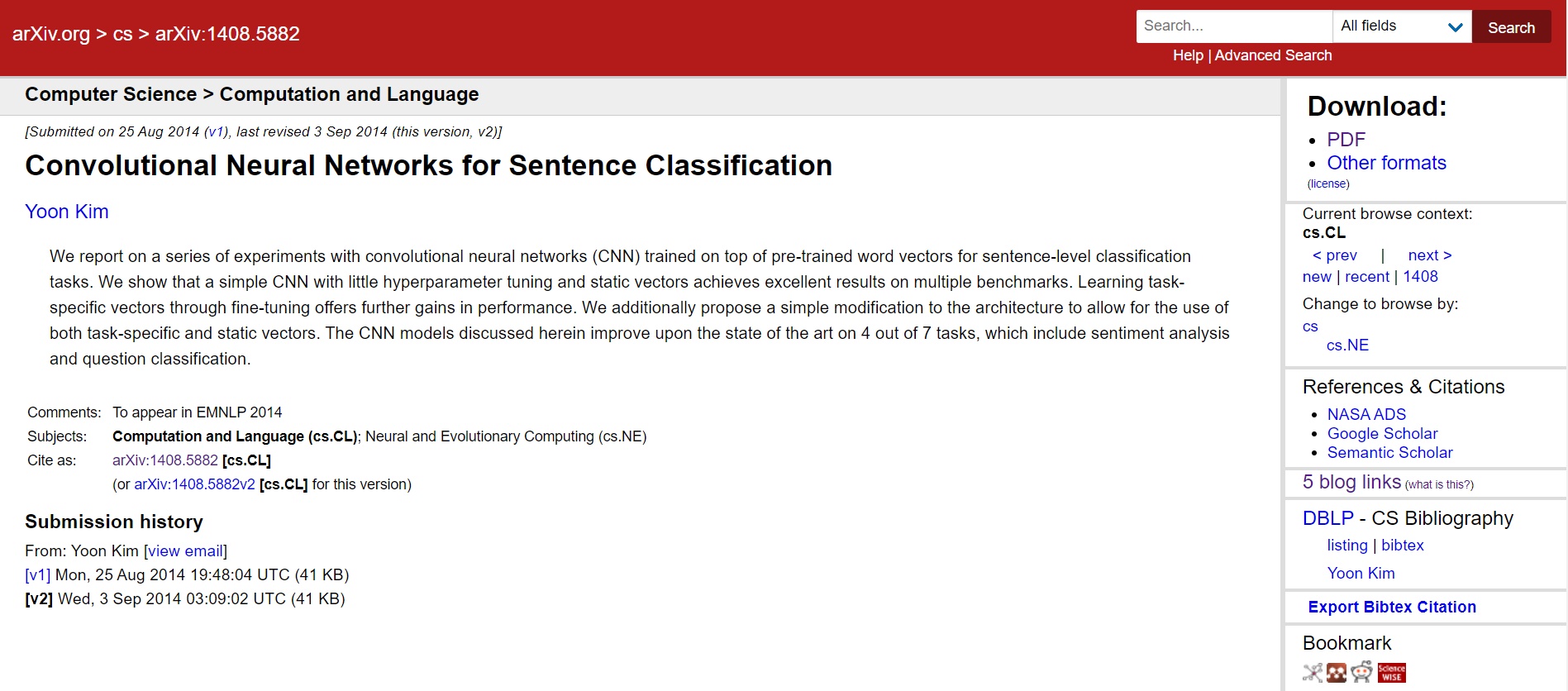 Obrázek 5: Stránka konkrétního záznamu. [zdroj obrázku: autor]
Obrázek 5: Stránka konkrétního záznamu. [zdroj obrázku: autor]
Kromě již známých informací, jež jsme měli k dispozici v nadhledu, máme možnost článek stáhnout ve formátu PDF. Je rovněž možné zvolit jiný formát, pokud je nějaký další k dispozici. Rozhraní nabízí i možnost dalšího vyhledávání příbuzných prací nacházejících se ve stejných kategoriích. Zajímavými funkcionalitami jsou možnost exportu citace ve formátu pro BibTeX (software pro uspořádání referencí) a tzv. Article Trackbacks – zpětné vyhledávání webových stránek, na kterých je daný článek řádně ocitován. Pro záznam z obrázku výše je nalezeno 5 blogů, v nichž byl zmíněn:
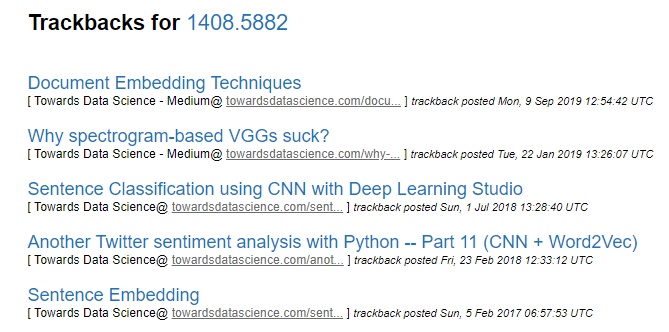 Obrázek 6: Trackbacks pro daný článek. [zdroj obrázku: autor]
Obrázek 6: Trackbacks pro daný článek. [zdroj obrázku: autor]
Jelikož je na ArXivu možné vyhledávat i podle autorů, každá stránka záznamu nabízí okamžité vyhledávání dalších autorových prací. Registrovaným uživatelům je rovněž k dispozici emailová adresa autora. Články je také možné přímo v rámci rozhraní uložit jako záložky. Momentálně ArXiv nabízí takovou funkci pro BibSonomy, Reddit, Mendeley a ScienceWISE. API posílá požadavek přímo do konkrétní aplikace prostřednictvím webového rozhraní a přesměrovává rovnou na stránku daného software v novém okně.
Velice užitečnou je přítomnost dalších specifických nástrojů, jež uložiště ArXivu nabízí. V první řadě je potřeba zmínit bibliografické nástroje využívající data třetích stran (Semantic Scholar) pro vyhledávání referencí a citací týkajících se vybraného článku. Výsledky, jež vrací nástroj Bibliographic Tools, je možné třídit podle jejich vlivu, autora, titulu či data zveřejnění a jsou zobrazeny ve dvou přehledných sloupcích. Tato funkcionalita do určité míry nahrazuje možnost filtrování podle popularity, neboť jejím prostřednictvím si lze nepřímo ověřit, nakolik je práce v odvětví uznávána, jaký je její dopad na daný obor a kolik dalších výzkumů využívá její poznatky pro své účely.
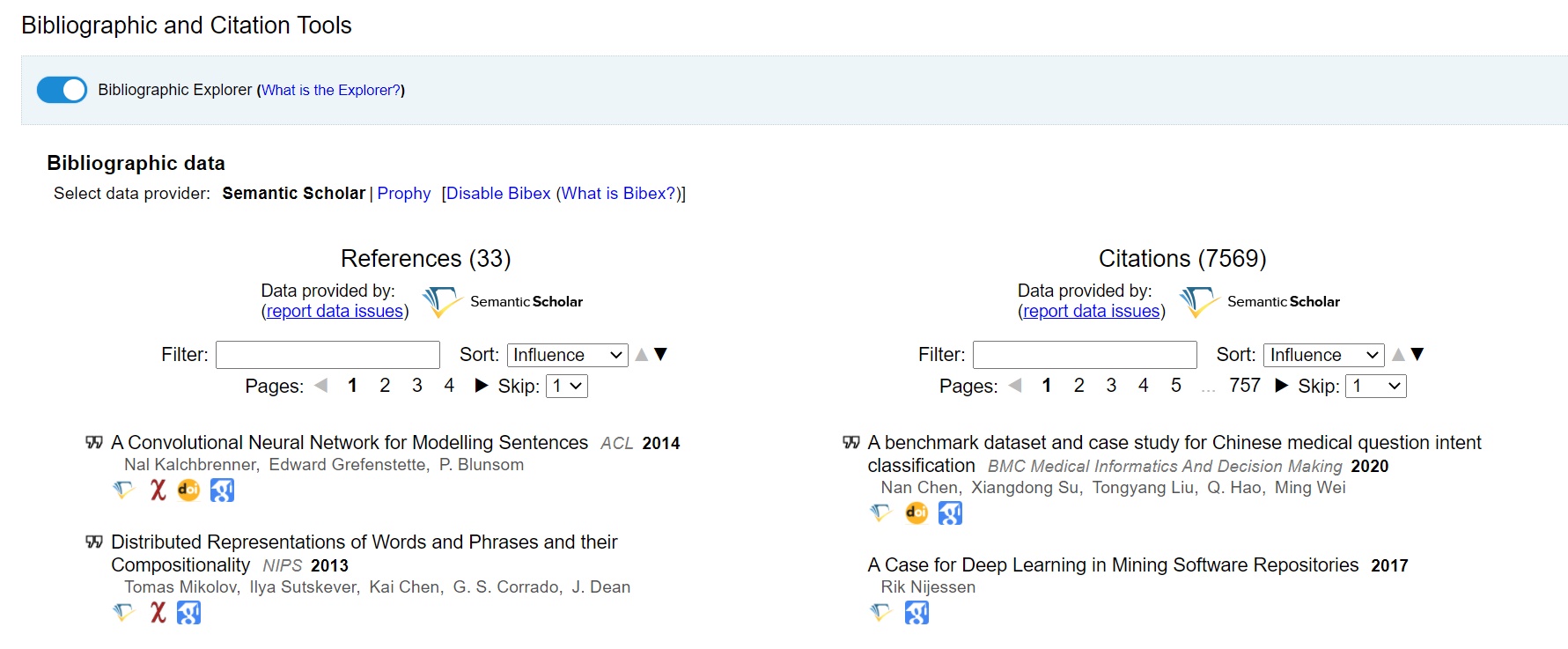 Obrázek 7: Bibliografické nástroje. [zdroj obrázku: autor]
Obrázek 7: Bibliografické nástroje. [zdroj obrázku: autor]
Kromě bibliografických nástrojů je ale k dispozici ještě jeden, jež dělá ArXiv natolik oblíbeným v řadách programátorů a vývojářů. Pokud hledáme řešení na konkrétní problém, jehož výstupem má být kód v konkrétním programovacím jazyce aplikující nalezené řešení, nelze se spoléhat pouze na samostatné články na ArXivu. Ty totiž kód neobsahují, nebo obsahují, ale jedná se pouze o pseudokód, náznak syntaxe, jež replikuje logiku daného řešení, je třeba ji nicméně ještě převést na syntaxi jazyka, v němž pracujeme.
Z tohoto důvodu existuje nástroj Code. Autoři článků mají možnost ke svým zveřejňovaným pracím přidat samostatně i kód, prostřednictvím kterého se dobrali ke zveřejňovaným výsledkům a úspěchům. Nelze se spoléhat na to, že na takového autora narazíme. Naštěstí zde existuje chytré spojení se stránkou Paperswithcode.com. Na té vývojáři z celého světa publikují svůj kód a díky citování článků, z nichž pochází inspirace jejich logického řešení, dokáže ArXiv každý kód propojený s daným článkem nabídnout uživateli k nahlédnutí.
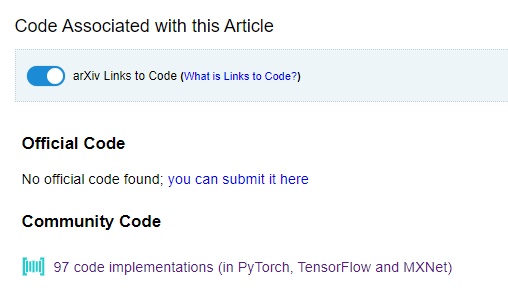 Obrázek 8: Propojení s Paperswithcode. [zdroj obrázku: autor]
Obrázek 8: Propojení s Paperswithcode. [zdroj obrázku: autor]
Závěr
ArXiv.org je online uložiště akademických článků, jež nebyly nutně ohodnoceny v rámci akademické obce. Obsahuje články z různých technických oborů příbuzných hlavně s fyzikou, matematikou a statistikou a je navržen tak, aby umožnil široké veřejnosti přístup k dokumentům o vědecké činnosti a poznatkům z ní vyplývajících. Počet článků uložených v databázi ArXivu se pomalu blíží ke dvěma milionům. Stránka nabízí chytré funkcionality, jež ji činí oblíbenou zejména mezi vývojáři strojového učení díky možnosti dohledání relevantního kódu, ale tematicky pokrývá daleko širší spektrum oborů.
Zdroje
[1] arXiv.org e-Print archive [online]. [cit. 30.1.2020]. Dostupné z: https://www.arxiv.org
[2] paperswithcode.com – The latest in Machine Learning [online]. [cit. 30.1.2020]. Dostupné z: https://www.paperswithcode.com
Seznam obrázků
Obrázek 1: Základní vyhledávání. [zdroj obrázku: autor]
Obrázek 2: Možnosti pokročilého vyhledávání. [zdroj obrázku: autor]
Obrázek 3: Výsledky hledání pomocí oborů. [zdroj obrázku: autor]
Obrázek 4: Výsledek vyhledávání. [zdroj obrázku: autor]
Obrázek 5: Stránka konkrétního záznamu. [zdroj obrázku: autor]
Obrázek 6: Trackbacks pro daný článek. [zdroj obrázku: autor]
Obrázek 7: Bibliografické nástroje. [zdroj obrázku: autor]
Obrázek 8: Propojení s Paperswithcode. [zdroj obrázku: autor]






{kind=link}